DataX 工作原理及源码解读 背景: 最近在工作中接触到阿里的数据同步工具datax,通过其实现了一些数据源的数据同步功能,虽然在官方文档中了解其工作原理,但是还是对其如何实现的可扩展的架构,和不同数据源之间导入导出的原理比较感兴趣,查看网上的一些介绍并没有深入源码,所以闲暇时间查看了datax的主流程代码,对此做了一下总结。
概述: 该文章主要内容如下:
datax 介绍
datax 工作原理
datax 如何本地调试
datax 源码分析
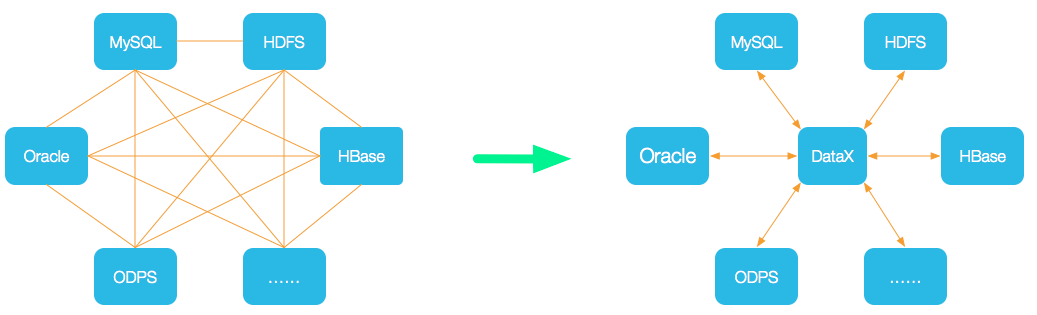
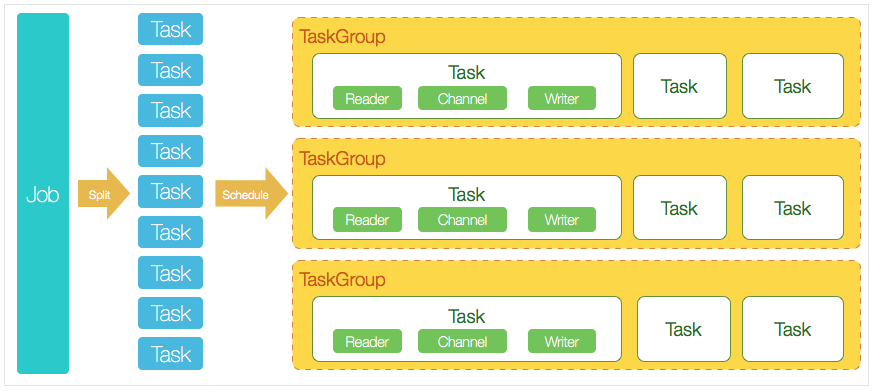
总结一、datax 介绍 github : datax 二、datax 工作原理 1. Datax核心架构图
job:datax 每执行一个同步任务则为一个job
task:datax 底层原理是将一个job,根据切分策略 拆分为多个task来进行并发执行,task是datax的最小执行单位。
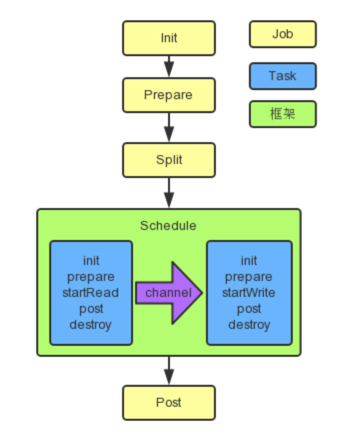
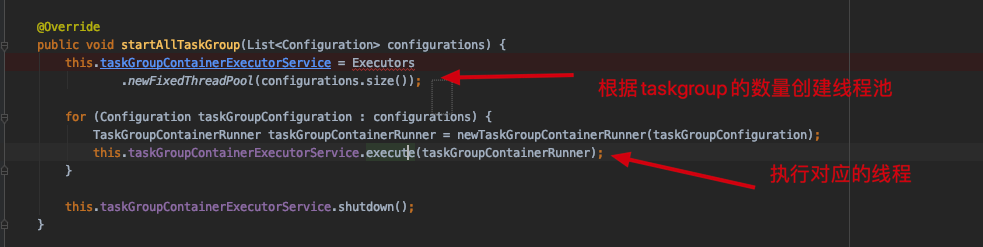
taskgroup:datax内部Scheduler模块会将拆分的task进行重组合生成taskgroup,创建对应数量的线程池进行任务数据的同步,同步顺序 Reader—>Channel—>Writer 2. Datax框架执行顺序 在看源码之前需要了解datax的执行顺序才能深入理解其工作原理,下面内容是在官方复制的,已经理解其内容的同学可以选择跳过。三、datax 如何本地调试
下载datax源码到本地1 git clone https://github.com/alibaba/DataX.git
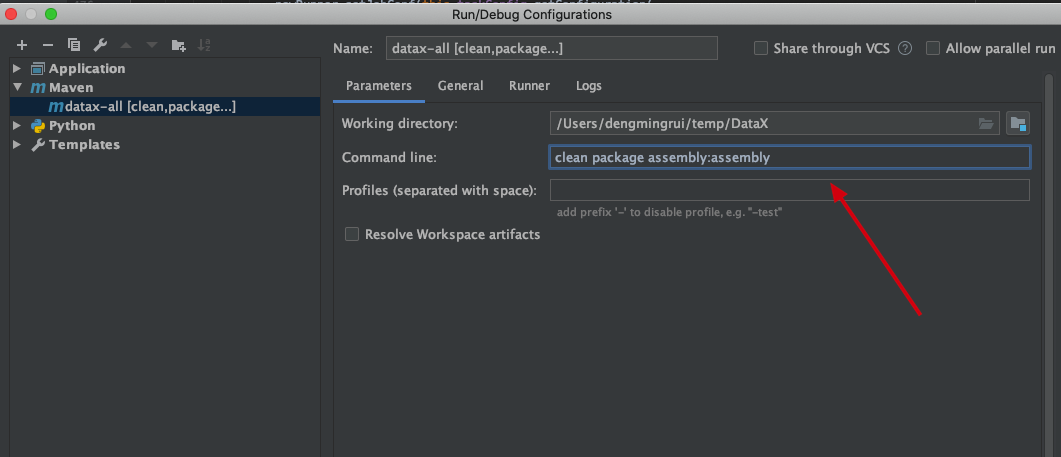
idea 打开项目进行编译
1 clean package assembly:assembly -Dmaven.test.skip=true
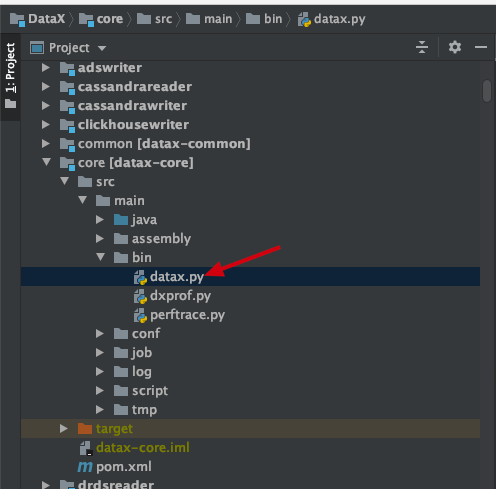
datax.py脚本在 /datax-core/bin/datax.py中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 if __name__ == "__main__": printCopyright() parser = getOptionParser() options, args = parser.parse_args(sys.argv[1:]) if options.reader is not None and options.writer is not None: generateJobConfigTemplate(options.reader,options.writer) sys.exit(RET_STATE['OK']) if len(args) != 1: parser.print_help() sys.exit(RET_STATE['FAIL']) // 这里生成执行脚本 startCommand = buildStartCommand(options, args) # print startCommand child_process = subprocess.Popen(startCommand, shell=True) register_signal() (stdout, stderr) = child_process.communicate() sys.exit(child_process.returncode)
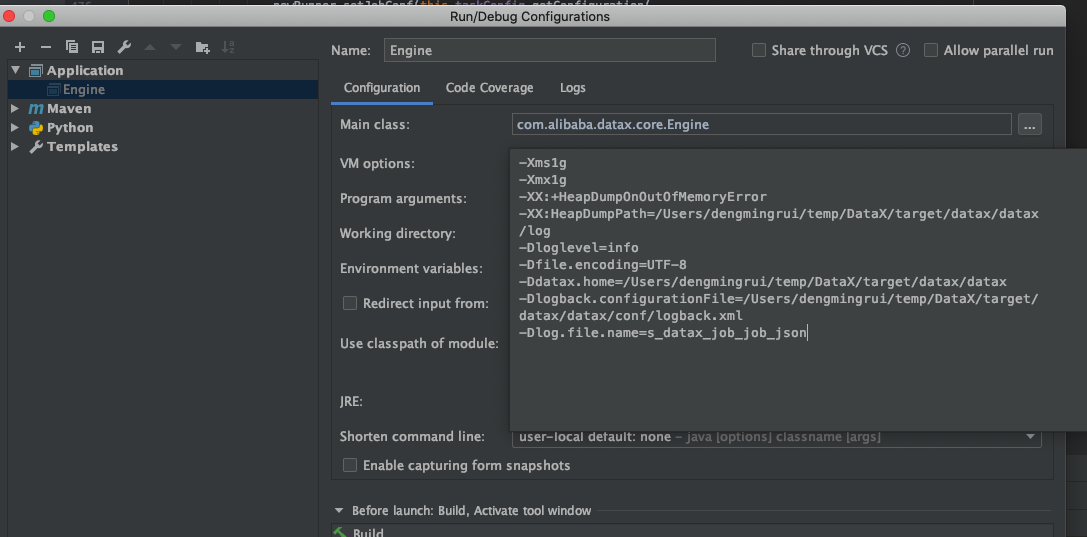
进行debug调试,获取执行datax的系统参数如下:
1 java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/dengmingrui/temp/DataX/core/src/main/log -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/dengmingrui/temp/DataX/core/src/main/log -Dloglevel=info -Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=/Users/dengmingrui/temp/DataX/core/src/main -Dlogback.configurationFile=/Users/dengmingrui/temp/DataX/core/src/main/conf/logback.xml -classpath /Users/dengmingrui/temp/DataX/core/src/main/lib/*:. -Dlog.file.name=grui_temp_datax_json com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job /Users/dengmingrui/temp/datax.json
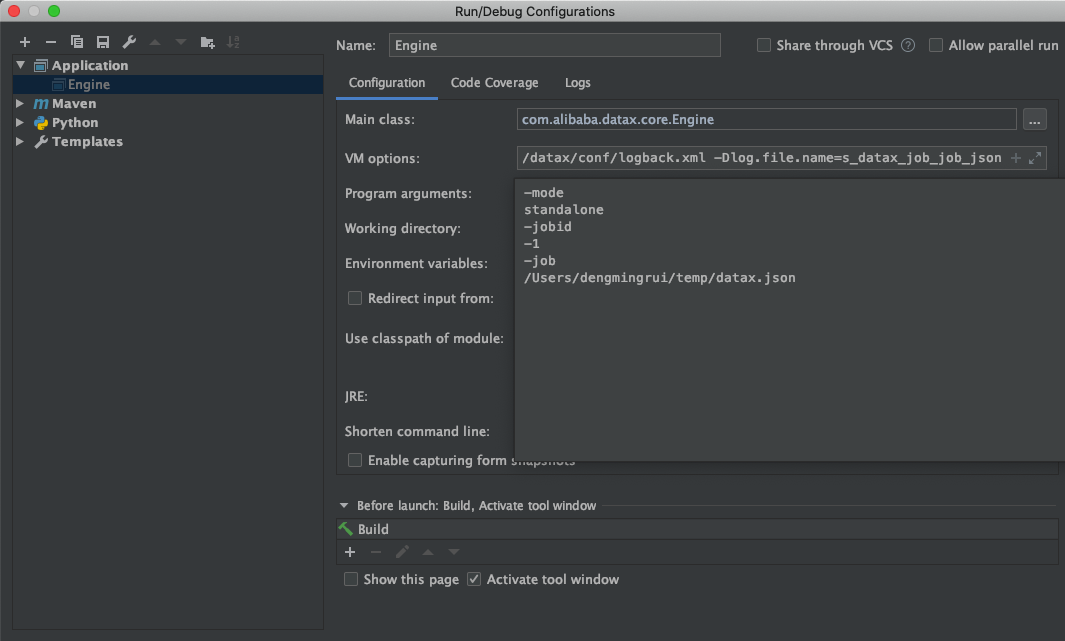
通过启动参数我们可以知道,datax的主方法在
1 -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/dengmingrui/temp/DataX/target/datax/datax/log -Dloglevel=info -Dfile.encoding=UTF-8 -Ddatax.home=/Users/dengmingrui/temp/DataX/target/datax/datax -Dlogback.configurationFile=/Users/dengmingrui/temp/DataX/target/datax/datax/conf/logback.xml -Dlog.file.name=s_datax_job_job_json
datax 源码分析 这次例子是将mysql中的数据同步到本地所以我的datax json文件内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 { "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "xxx", "password": "xxx", "column": [ "xxx", "xxx", "xxx", "xxx", "xxx", "xxx" ], "splitPk": "id", "connection": [ { "table": [ "xxxx" ], "jdbcUrl": [ "xxxxx" ] } ] } }, "writer": { "name": "txtfilewriter", "parameter": { "path": "/Users/dengmingrui/temp/data", "fileName": "test", "writeMode": "truncate", "dateFormat": "yyyy-MM-dd", "fieldDelimiter": "," } } } ], "setting": { "speed": { "channel": 5 } } } }
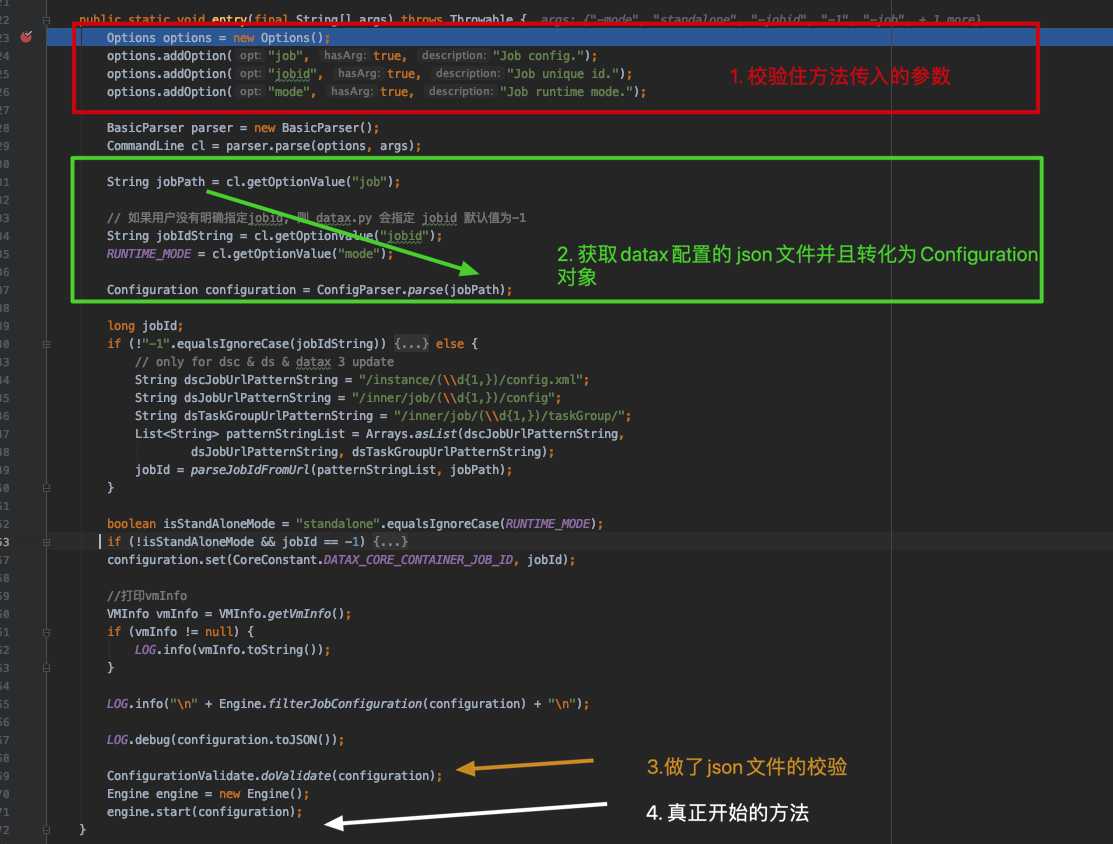
代码debug 直接执行 Engine.entry(args) 方法,具体逻辑如下
进行main方法参数提取
将datax的json文件转化成Configuration对象(json文件的内容直接通过这个对象可以获取到对应的属性)
对datax json文件做了校验
执行engine.start(configuration)方法
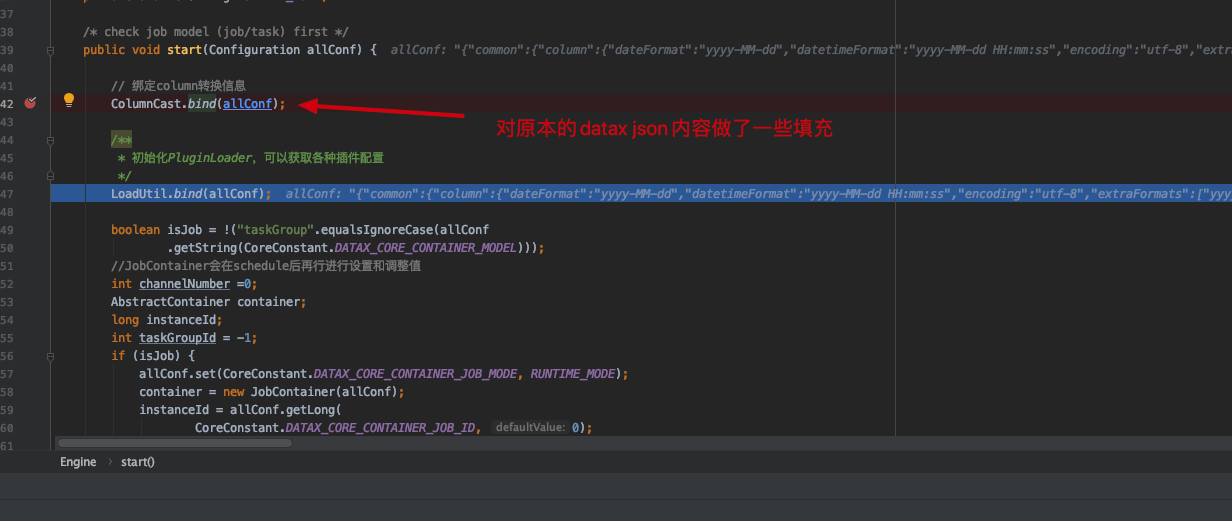
start()方法
1 2 // 该方法对datax 的json配置文件做了一些填充 ColumnCast.bind(allConf);
该方法对datax 的json配置文件做了一些填充,填充内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 { "common":{ "column":{ "dateFormat":"yyyy-MM-dd", "datetimeFormat":"yyyy-MM-dd HH:mm:ss", "encoding":"utf-8", "extraFormats":[ "yyyyMMdd" ], "timeFormat":"HH:mm:ss", "timeZone":"GMT+8" } }, "core":{ "container":{ "job":{ "id":-1, "reportInterval":10000 }, "taskGroup":{ "channel":5 }, "trace":{ "enable":"false" } }, "dataXServer":{ "address":"http://localhost:7001/api", "reportDataxLog":false, "reportPerfLog":false, "timeout":10000 }, "statistics":{ "collector":{ "plugin":{ "maxDirtyNumber":10, "taskClass":"com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector" } } }, "transport":{ "channel":{ "byteCapacity":67108864, "capacity":512, "class":"com.alibaba.datax.core.transport.channel.memory.MemoryChannel", "flowControlInterval":20, "speed":{ "byte":-1, "record":-1 } }, "exchanger":{ "bufferSize":32, "class":"com.alibaba.datax.core.plugin.BufferedRecordExchanger" } } }, "entry":{ "jvm":"-Xms1G -Xmx1G" }, "job":Object{...}, "plugin":{ "reader":{ "mysqlreader":{ "class":"com.alibaba.datax.plugin.reader.mysqlreader.MysqlReader", "description":"useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.", "developer":"alibaba", "name":"mysqlreader", "path":"/Users/dengmingrui/temp/DataX/target/datax/datax/plugin/reader/mysqlreader" } }, "writer":{ "txtfilewriter":{ "class":"com.alibaba.datax.plugin.writer.txtfilewriter.TxtFileWriter", "description":"useScene: test. mechanism: use datax framework to transport data to txt file. warn: The more you know about the data, the less problems you encounter.", "developer":"alibaba", "name":"txtfilewriter", "path":"/Users/dengmingrui/temp/DataX/target/datax/datax/plugin/writer/txtfilewriter" } } } }
可以看到我们原来配置的json内容只是整个json的job部分,其他内容都是由 ColumnCast.bind(allConf)方法补充的。后面调用了
1 2 AbstractContainer container = new JobContainer(allConf); container.start();
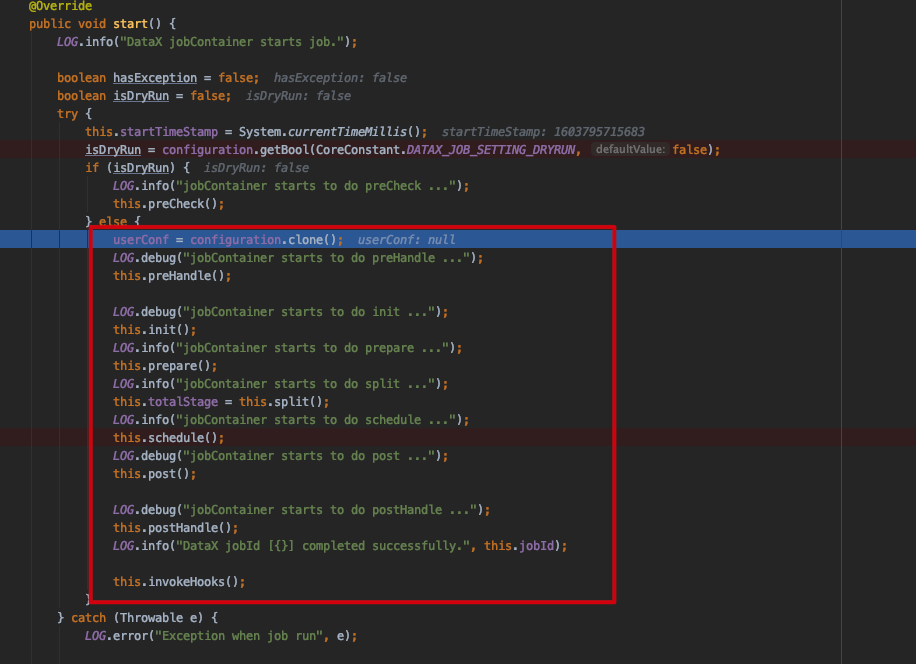
JobContainer start()方法
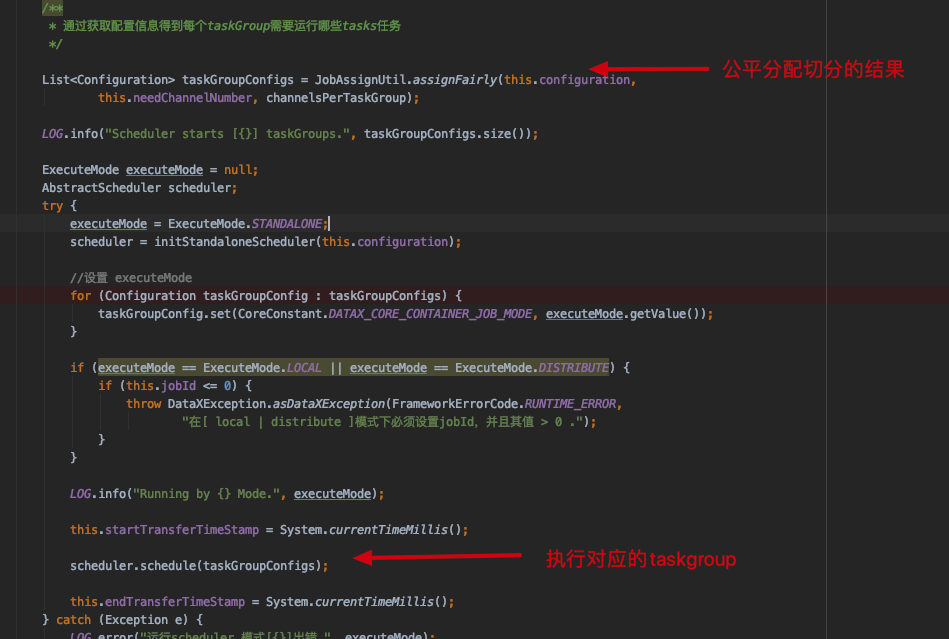
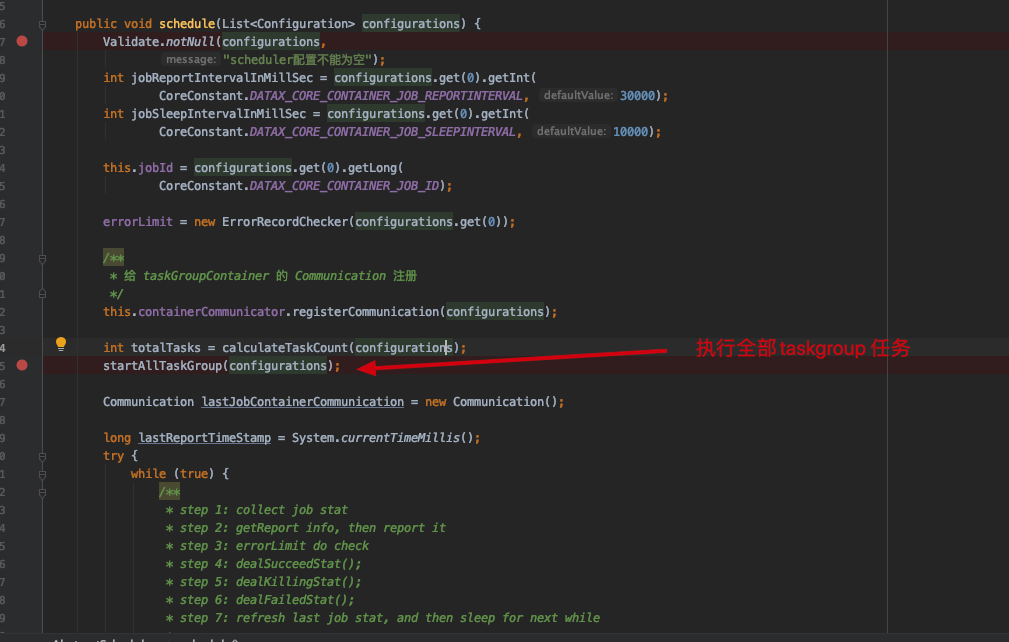
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 前置处理 this.preHandle(); // 初始化 this.init(); // 准备方法 this.prepare(); // 任务切分 this.split(); // 执行调度 this.schedule(); // ... this.post(); // ... this.postHandle(); this.invokeHooks();
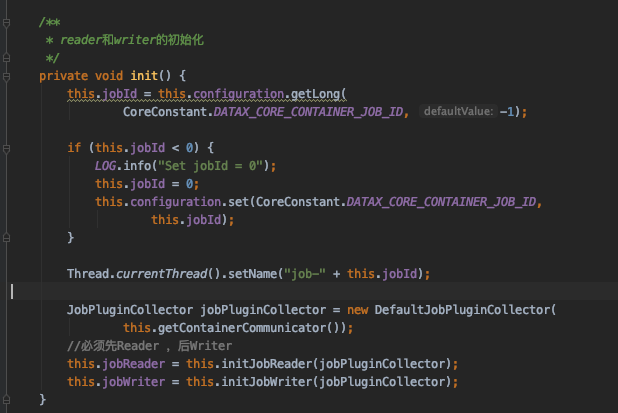
其中核心的方法为 this.init() 、this.split()、 this.schedule() 本次重点只看这几个方法init()方法 initJobReader 方法
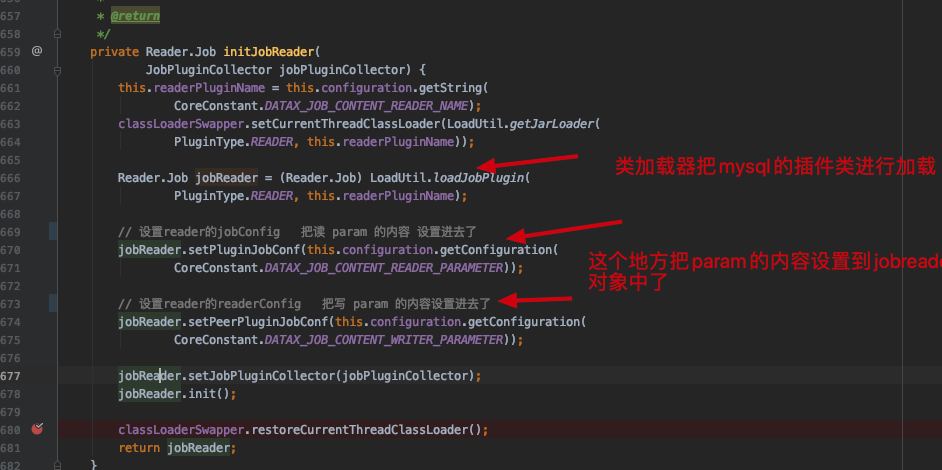
1 LoadUtil.loadJobPlugin(PluginType.READER,this.readerPluginName)
提取Configuration 对象参数的部分插入到 jobReader 的pluginJobConf 属性中,具体内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 // pluginJobConf { "column":[ "id", "project_id", "alarm_time", "job_id", "job_name", "receiver" ], "connection":[ { "jdbcUrl":[ "xxxx" ], "table":[ "xxxxx" ] } ], "password":"xxxxx", "splitPk":"id", "username":"xxxx" } // peerPluginJobConf { "dateFormat":"yyyy-MM-dd", "fieldDelimiter":",", "fileName":"test", "path":"/Users/dengmingrui/temp/data", "writeMode":"truncate" }
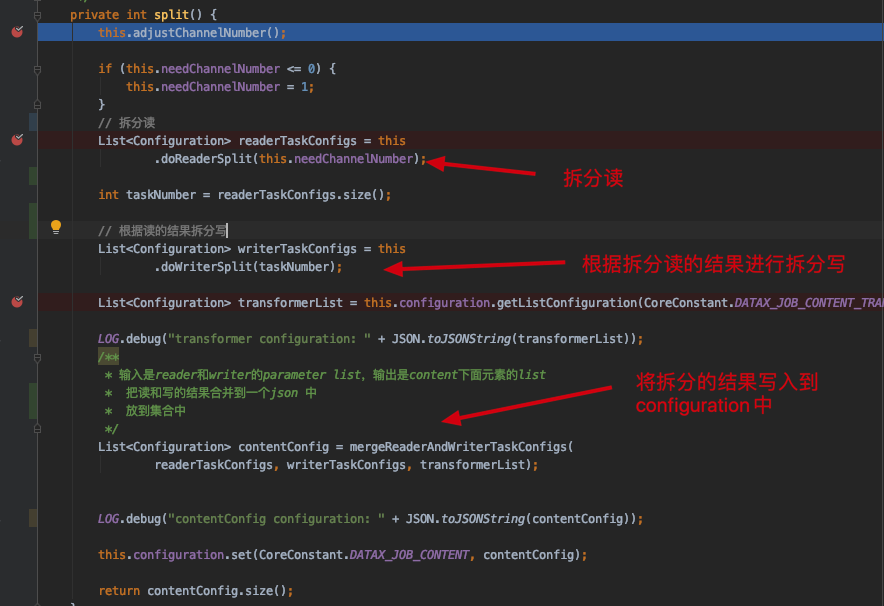
最终执行jobReader.init(); mysql插件的init方法进行初始化。split()方法
拆分reader
根据reader的拆分结果拆分writer
将reader 和 writer的拆分结果 合并到Configuration对象中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 { "common":Object{...}, "core":{ "container":{ "job":Object{...}, "taskGroup":{ "channel":5 }, "trace":Object{...} }, "dataXServer":Object{...}, "statistics":{ "collector":Object{...} }, "transport":Object{...} }, "entry":{ "jvm":"-Xms1G -Xmx1G" }, "job":{ "content":[ Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, { "reader":{ "name":"mysqlreader", "parameter":{ "column":"id,xx,xx,job_id,xxx,xxx", "columnList":[ "xxx", "xxx", "xxx", "xxx", "xxxx", "xxxx" ], "fetchSize":-2147483648, "isTableMode":true, "jdbcUrl":"jxxxxxx", "loadBalanceResourceMark":"xxxx", "password":"xxxxxx", "pkType":"pkTypeLong", "querySql":"select xxx,xxxx,xxxx,xxxx,xxxx,xxxx from xxxx where (2977 <= id AND id < 3473) ", "splitPk":"id", "table":"xxxx", "tableNumber":1, "username":"xxxx" } }, "taskId":6, "writer":{ "name":"txtfilewriter", "parameter":{ "dateFormat":"yyyy-MM-dd", "encoding":"UTF-8", "fieldDelimiter":",", "fileName":"test__ad112b06_6dd1_4708_a608_890fbf55f7b1", "path":"/Users/dengmingrui/temp/data", "writeMode":"truncate" } } }, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...}, Object{...} ], "setting":{ "speed":{ "channel":5 } } }, "plugin":Object{...} }
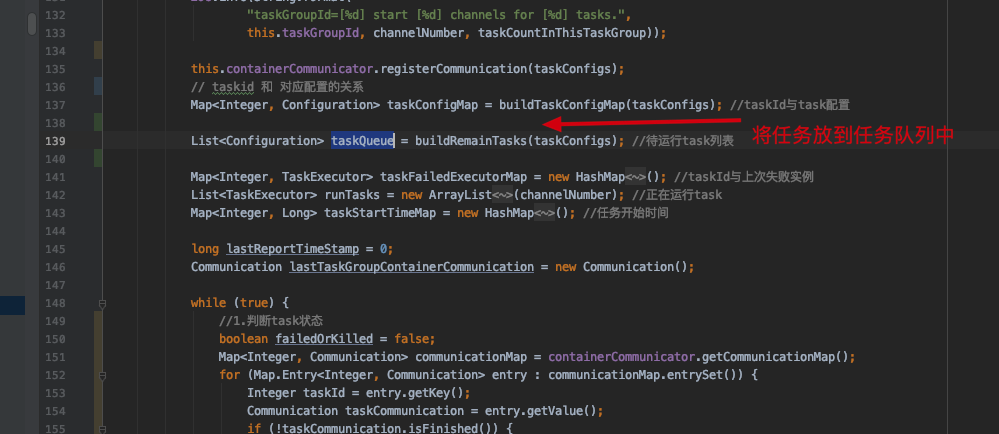
可以看到job.content数组下面多了很多小job,这里每个小job就是我们一开始说的task,每一个task 都有对应reader和writer的数据源信息。datax这里把json完的很6schedule()方法
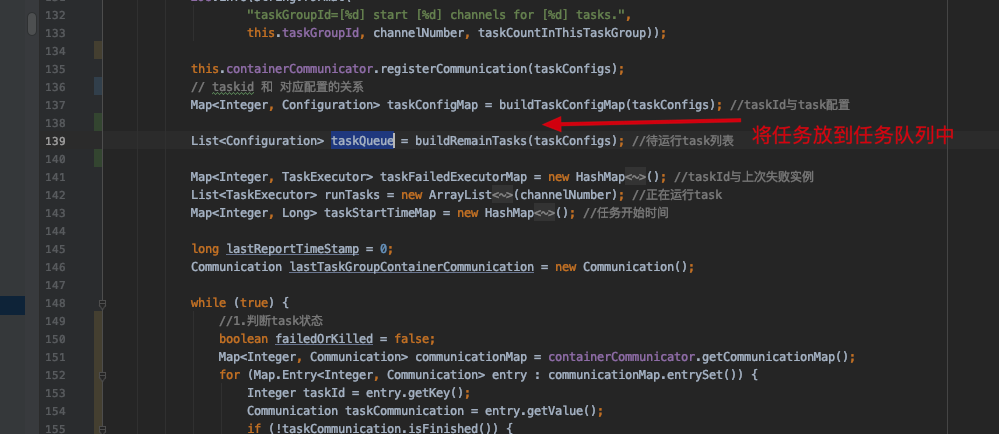
最终线程执行的方法在TaskGroupContainer累的run()方法中,这里逻辑太长了就不截图了
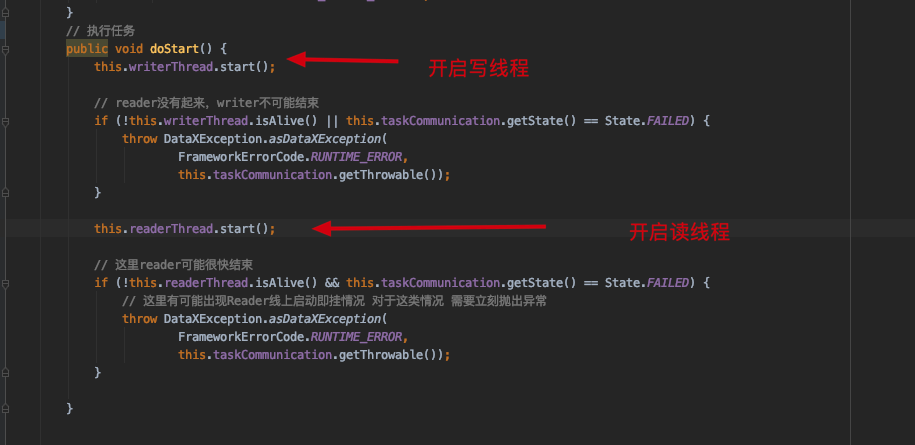
doStart() 方法
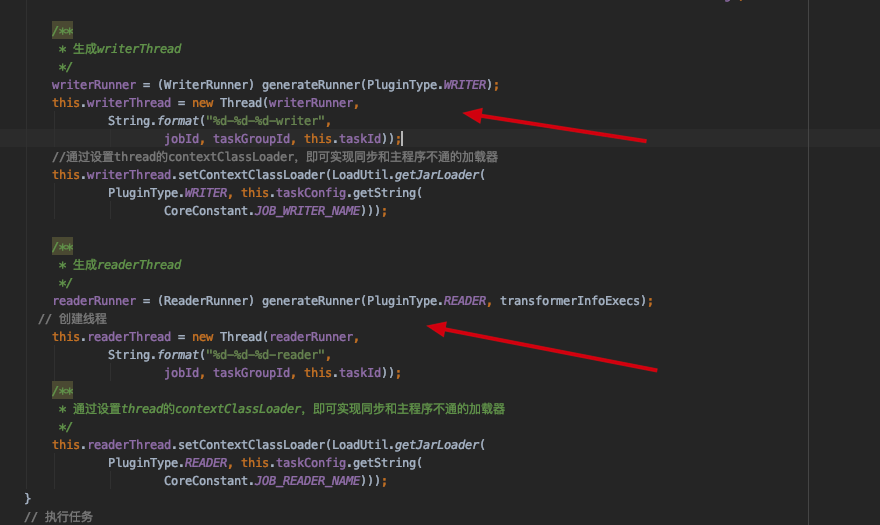
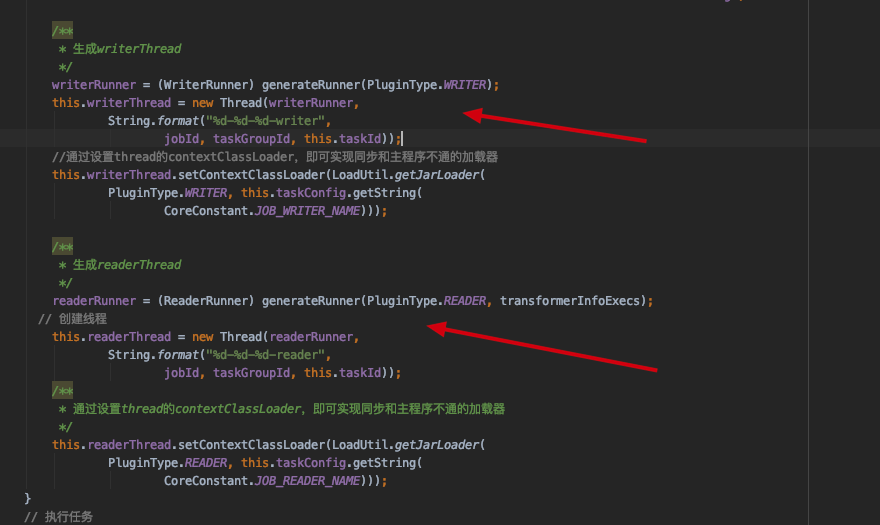
readerThread 和 writerThread 是什么时候初始化的呢?
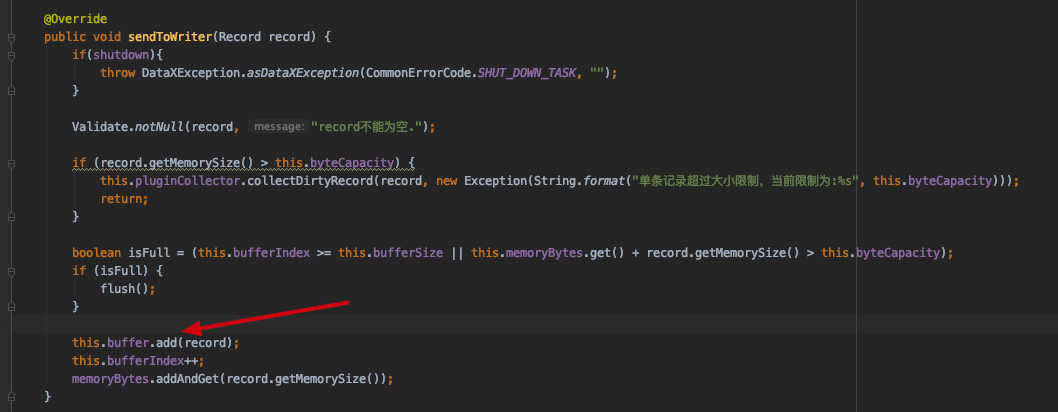
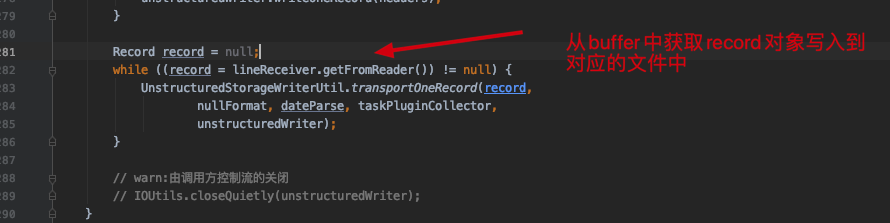
reader 和 writer 之间是如何通信的呢? 答: Record 对象,reader 插件在读取之后,将对应的数据封装到Record对象,存储在集合中,writer 读取对应的集合数据在执行写入到目标数据源。下面是mysql插件的逻辑
1 taskWriter.startWrite(recordReceiver);
总结 本次查看了datax的源码,对datax有了更生层次的理解,datax的插件架构还是学习到了,并且整个任务全程用json对应的Configuration类贯穿整个链路非常使得代码非常灵活。datax对任务的拆分设计和精准的速度控制逻辑的设计后面也有借鉴的地方,类加载器的使用非常巧,代码整体上还是写的非常易懂的看起来并不吃力。其实datax的架构和执行逻辑文档上写的还是很清楚的,如果感兴趣的话可以快速看一下源码的。
 微信
微信 支付宝
支付宝