10分钟了解SimbaFs解决hadoop存算分离问题
一、前言
众所周知传统的 Apache Hadoop 的架构存储和计算是耦合在一起的, HDFS 作为其分布式文件系统也面临一些问题。如: 存储空间或者计算资源不足两者只能同时扩容、扩容效率低、额外增加成本、灵活性差等。本文会大家回顾Hadoop的传统架构来分析上述问题以及Hadoop实现存算分离的方案和DataSimba的对于Hadoop存算分离的最佳实践。
二、Hadoop分布式文件系统(HDFS)的架构和问题
HDFS的架构: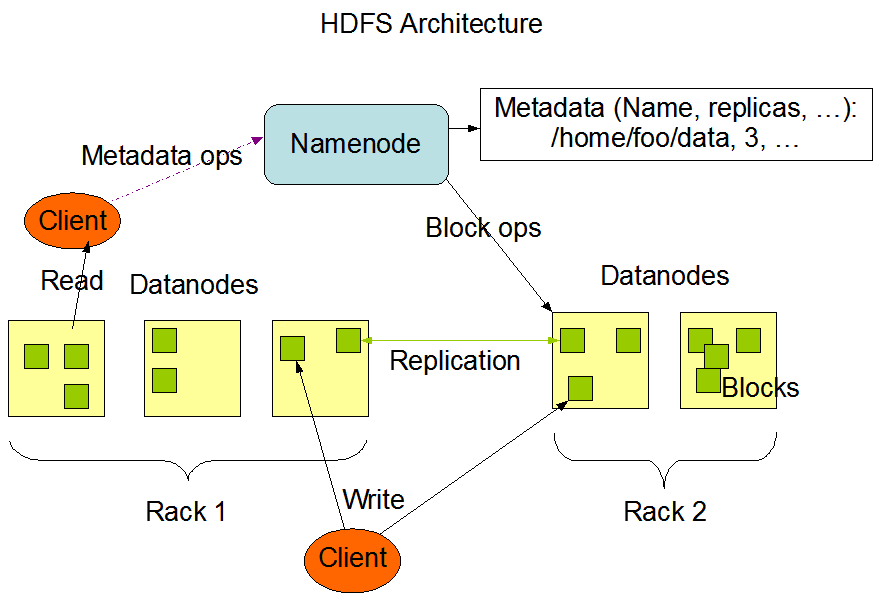
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
- Namenode:
- Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问
- Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。
- Datanode:
- 集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
- HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
- Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
- Client:
- 用户操作HDFS文件进行创建、删除、移动或重命名操作的客户端。
Hadoop分布式文件系统的设计目标:
- 适合运行在通用硬件和廉价机器(commodity hardware)上的分布式文件系统
- 机器的硬件错误常的态化,让HDFS具有错误检测和快速、自动的恢复能力是最核心的架构目标
- 数据批处理关键的在于数据访问的高吞吐量,而POSIX标准设置的很多硬性约束对HDFS应用系统不是必需的。为了提高数据的吞吐量,在一些关键方面对POSIX的语义做了一些修改。
- HDFS应用一次写入多次读取”的文件访问简单一致性模型
- 移动计算的思想: 进行一次请求计算数据距离越近就越高效,在海量数据处理下hadoop将计算逻辑移动到存储节点。
- 数据切分成块、数据复制副本(容错)、数据副本分布策略、机架感知、副本选择等特性来保证hdfs可靠性和提高性能的关键。
- Datanode节点周期性地向Namenode发送心跳信号、负载均衡策略、HDFS文件内容的校验和(checksum)检查保证HDFS的健壮性和可靠性。
Hadoop分布式文件系统的问题:
- 计算存储耦合:
上面说过HDFS采用移动计算的思想,计算的时候只需要将计算代码推送到存储节点上,即可在存储节点上完成数据本地化计算,Hadoop 中的集群存储节点也是计算节点。所以当存储空间或计算资源不足时,只能同时对两者进行扩容。如果用户的计算需求远远大于存储需求,此时扩容集群会造成存储的浪费,相反则计算资源被浪费。 - 扩容问题:
集群节点增多,扩容成本增加,风险增加 - HDFS性能问题:
HDFS NameNode的全局锁虽然简化了锁模型降低了复杂度,但是全局锁最大的缺点就是容易产生性能瓶颈 - HDFS成本问题:
在HDFS文件系统中典型文件大小一般都在G字节至T字节,由于HDFS的副本特性一份文件至少会存储3份,这些额外的空间会带来存储成本额外的提高
针对上面一些问题,现在Hadoop采用存算分离的架构的方案趋势越来越明显
三、Hadoop 实现存算分离方案:
- 方案一: Hadoop 兼容的文件系统:

上图是Hadoop3.X 目前兼容的文件系统,支持aws s3、腾讯云 cos、阿里云 oss存储,可以看到用户在上传数据时候,需要调用对应云服务厂商的sdk进行数据的写入。下载文件也是一样的原理。不过为什么现在可以使用这种方式实现Hadoop的计算存储分离呢?
举一个例子日常生活中遇到的经历:家里带宽自从升级到100mpbs,从来不保存电影,要看直接下载,基本几分钟就好了。这在几年前不可想象。
带宽的速度,特别是机房内带宽的速度,已经从1000mps、2000mps、10000mps,甚至100000mpbs。但是磁盘的速度基本没有太大的变化。因为硬件的变化,带来了软件架构的变化。
虽然方案一可以实现计算存储分离,但是基本架构上还是存在问题:虽然带宽增加,但是如果Hadoop集群机房和对应的对象存储机房距离较远,网络抖动等原因加大了传输失败的几率,还有比如判断一个目录需要多次的refs请求才能完成操作,多次请求会对性能造成影响。
- 方案二: 云原生的Hadoop文件系统 SimbaFs:
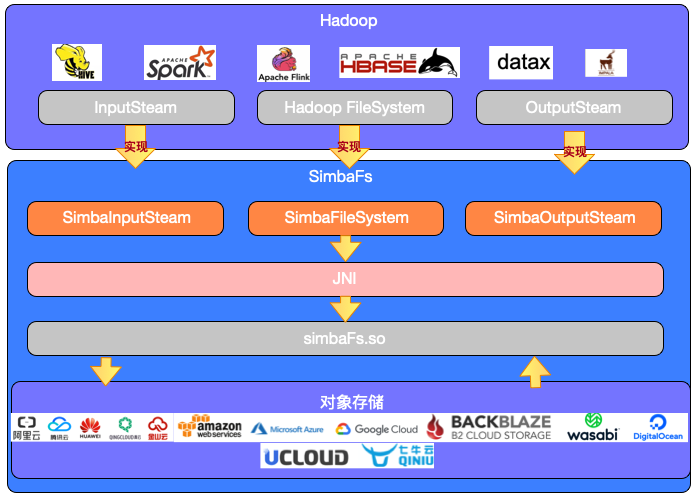
上图是SimbaFs的架构,SimbaFsClient是一个java开发的jar包,兼容Hadoop文件系统,按照Hadoop FileSystem API规范来实现。主要实现了Hadoop FileSystem的list、delete、rename、mkdir等接口,而InputStream和OutputStream主要实现了对文件读写优化相的等实现(预读、缓存读、异步写、批量写、文件压缩)。SimbaFs client通过JNI (Java Native Interface) 技术转换为本地simbafs.so的调用实现相关方法,完成文件的上传/下载操作。
- 压测情况:
由于对于读做了预读和缓存操作,对于写的操作通过异步写和批量写的优化所以SimbaFs的性能也是非常优秀的。我们在发行版本为cdh5的集群, hdfs版本为2.6做了测试。使用3台阿里云4核14g的ecs做压力测试,对象存储选择的是oss,并且保证集群节点和oss在同一机房。下面是关于create_write、open_read、rename、delete 等操作的压测结果。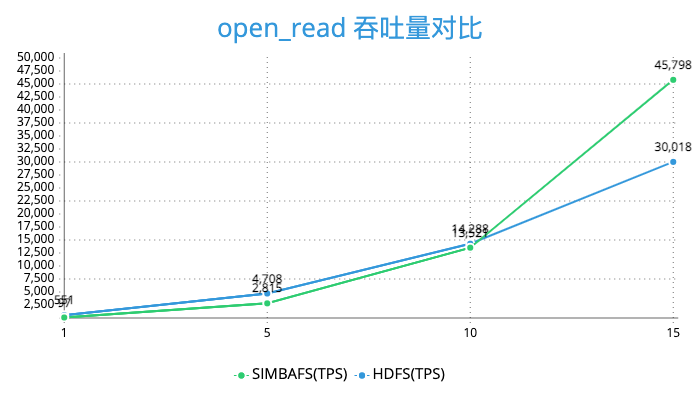
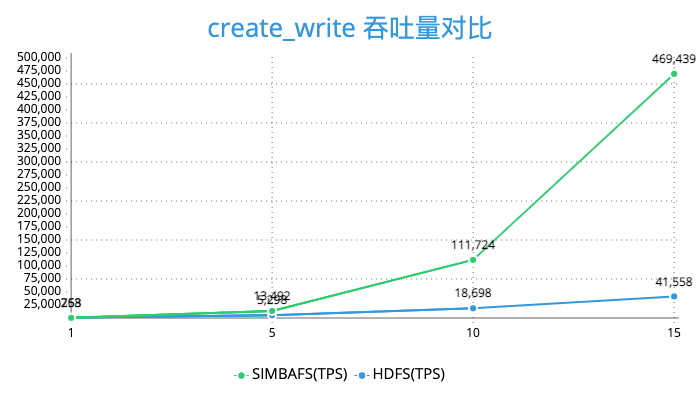
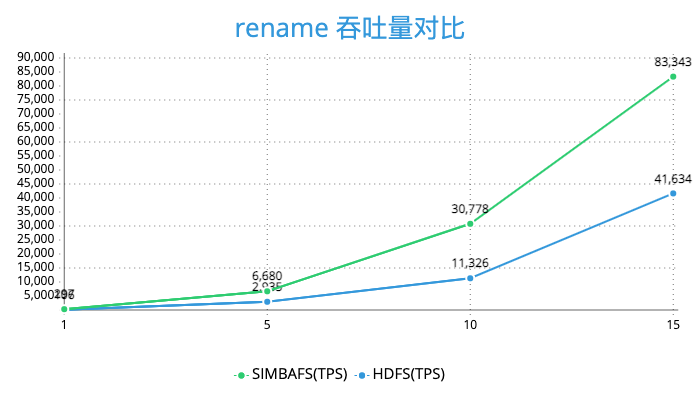
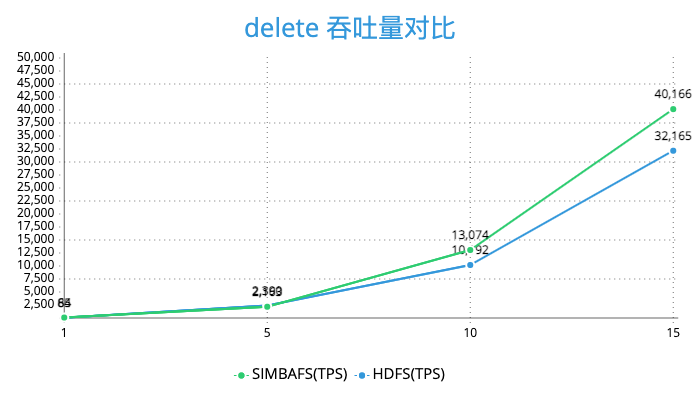
可以看到SimbaFs的性能在open_read、create_write、rename是远好于HDFS的
四、小节
本文先回顾了传统Hadoop分布式文件系统的架构和问题,以及实现Hadoop存算分离的方案,并详细介绍了DataSimba对存算分离的SimbaFs的实现原理和压测情况。最后真心希望本文对你所有帮助。
 微信
微信 支付宝
支付宝